
Methodology
Workflow
Among the goals of MPCD is an exact representation of the texts as they appear in the selected manuscripts. Although the manuscripts are transliterated and transcribed in a thorough fashion [Orthographic and Phonographic Annotation], the annotation work does not start from scratch. To accelerate the process, a pre-existing transcription is used as a basis for the annotation work. Proceeding from this transcription, a preliminarily annotated text is prepared by means of a module that we refer to as 'pre-annotation'. Through 'pre-annotation', the transcribed text is tokenized and the individual tokens are lemmatized. Moreover, a default transliteration, a morphological annotation and a default meaning are assigned to each token. The current rule-based pre-annotation, which relies on preexisting glossaries, will be replaced by a neuronal, semi-automated annotation in the course of the project.
Following pre-annotation, the work of the philologists sets in, who cross-check the pre-annotated text against the manuscript. Transliteration and transcription are carefully adapted to the data found in the actual manuscript [Orthographic and Phonographic Annotation]. Subsequently, the morphological and semantic annotation [Grammatical Annotation, Semantic Annotation] are adapted according to the context. A few selected texts also receive a manually prepared syntactic annotation. The annotations, especially on the semantic level, form the basis for our lexicographical work [Dictionary].
By means of the texts that have been provided with a syntactic annotation, supported by the philologists' reviewing of the automatically produced output, the tool employed for the semi-automated annotation will be continually improved. Automatically and manually produced annotations are kept strictly separate, and the distinction between them will be fully transparent to the end user.
Orthographic Annotation
Each token is provided with a transliteration and a transcription. The transliteration depicts all kinds of spelling variation found in the manuscripts, taking into account diacritics as well as errors and other abnormal spellings of words. This will allow for an exact digital representation of the manuscript and provide a basis for codicological and stemmatological analyses.
The transcription represents a phonemic (phonographic) interpretation of a given token. It essentially follows common views on the phonology of Sasanian-period Middle Persian as established in the works of authors such as MacKenzie 1971 (A Concise Pahlavi Dictionary) and Durkin-Meisterernst 2004 (Dictionary of Manichaean Middle Persian and Parthian). But at the same time, it also takes into account certain peculiar spellings as found in the manuscript at hand, as long as they seem to depict genuine phonetic by-forms. In this way, the transcription also depicts some of the diachronic and diatopic variation that is reflected in the manuscripts.
Finally, each token is attributed to an abstract lemma, which shows neither spelling nor phonemic-phonetic variation.
Grammatical Annotation
Each token receives a morphological and a syntactic annotation based on the standard ‘Universal Dependencies’. As with the semantic annotation, we disambiguate form and function depending on the context:
- abar ‘up, above’ as ‘Adverb’ with the feature “AdvType=Loc” (i.e. local adverbial)
- abar ‘on, over’ as ‘Adposition’ with the feature “AdpType=Prep” (i.e. preposition)
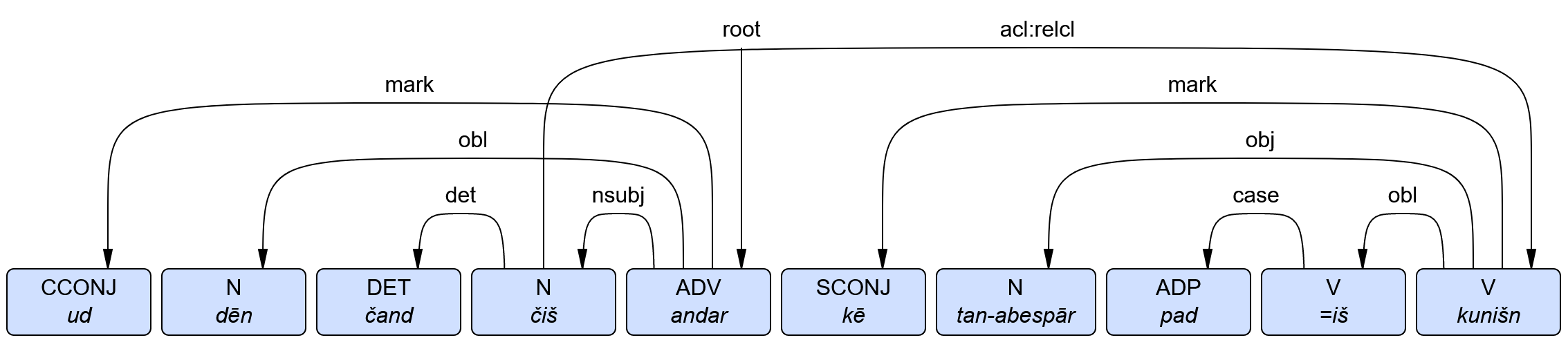
“Head” or “Root” of the sentence is the verb of the main clause “(be) inside”. The head of each phrase (subject, adpositional expression, subclause, etc.) is related to the head of the main clause. The dependencies are identified according to the Universal Dependencies Standard (for instance, adpositions are related by “case” to their complement).
By means of queries that combine both morphological and syntactic information, we are able to give quantitative analyses of Middle Persian grammar, set up text-specific grammars and identify diachronic as well as dialectal differences. In combination with the semantic analysis, the morpho-syntactic annotation can be used for historical analysis, e.g. which words can be plural? Which concepts can be realized as subjects?
Semantic Annotation
The semantic annotation of the texts is carried out on two levels. On the lexical level, each token is assigned a meaning in accordance with the given context. If the required meaning is already available in the provisional lemma entry of the dictionary, the philologist is able to select it from a list of proposed meanings. If it is not yet available, the new meaning is first added to the existing ones to be then selected by the annotator in the usual way.
Particular attention is given to technical terms, that is, words that show a special meaning when used in a specific semantic context, in which case they cannot be rendered literally. In preparation of their future lexicographical processing, technical terms are gathered in a separate list already during the annotation work. There, they are assigned to one or several semantic categories (legal, theological, ritual, astronomical, etc.). They are, moreover, supplied with a definition and various further indications (e.g. regarding their etymology), as well as with cross-links to other lemmata and references to the relevant secondary literature. This serves as a preliminary step to the future taxonomic categorisation of the lemmata in the dictionary. As the meaning of a technical term, we either retain the Middle Persian term itself, or we choose or coin an equivalent English technical term.
On the sentence level, the annotator provides each sentence with a working translation, which is primarily meant to be used internally during the later stages of the lexicographical work (see Dictionary). Complementing these working translations, an increasing amount of older translations quoted from the scholarly literature will be added to the sentences.
Intertextuality
In Zand texts, i.e., Middle Persian (MP) texts translated from Avestan (Av.), the annotation involves a matching of MP words with their underlying Av. forms and lemmata. See the following example from Yasna 9.1:
Through their shared passage IDs, the Zand texts incorporated in the MPCD database are linked up with their Av. base texts as presented in the database of the CAB project (“Corpus Avesticum Berolinense”, FU Berlin).
The linking-up of the MP and Av. texts will provide opportunities for various kinds of queries into the correspondences between the MP and Av. lexicon and vice-versa.
Often the mutual relation between the MP text and its Av. basis cannot be fully captured on the word level, but it requires taking into account the phrase level (cf. MP az ōy : Av. dim in the example above). Based on the annotation of the MP text according to Universal Dependencies, the attribution of entire MP phrases to a given Av. form will also be possible. This will provide a basis for enquiries such as “which types of MP adpositional constructions are used to render which Av. case forms?”
Parallel passages within the Zand corpus are also going to be linked up, so that it will become possible to evaluate diverging meanings of similar or mutually identical Av. passages.
Moreover, the incorporation of the Zand texts into the corpus of MPCD will enable the identification of Zand-specific vocabulary in the context of our dictionary.
Dictionary
Work on the dictionary consists of two basic steps. The first one takes place in the form of the semantic annotation that is done during the processing of the corpus. In the course of the annotation, each token is assigned to a lemma as well as to a specific meaning, which enables the user to retrieve the attestations of that specific meaning. The semantics and usage of technical terms receive special attention already during the annotation work.
The second step in the preparation of the dictionary will be initiated in the second half of the runtime of the project and focuses on the lexicographical work on the dictionary articles. For this purpose, the meanings of each lemma will be hierarchically arranged and linked to a taxonomic concept. This procedure allows for a usage of the dictionary from an onomasiological perspective, which will be particularly useful for researchers coming from other fields.
A typical dictionary entry will comprise the following types of information: hierarchically arranged meanings, conceptual categories, orthographic and phonological variants, PoS, attestations, cross-links to other lemmata ((members of) compounds, synonyms and antonyms), valency and phraseology, external cross-links (e.g. to Avestan equivalents in the “Corpus Avesticum Berolinense”), and bibliographical references.


